Trouble Uploading Photos to New Airbnb Listing
Categorizing Listing Photos at Airbnb
Large-calibration deep learning models are changing the way nosotros recollect about images of homes on our platform.
Authors: Shijing Yao, Qiang Zhu, Phillippe Siclait

Airbnb is a marketplace featuring millions of homes. Travelers around the world search on the platform and discover the best homes for their trips. Bated from location and price, listing photos are i of the most critical factors for decision-making during a guest'south search journey. However until very recently, we knew very picayune nearly these of import photos. When a guest interacted with listing photos of a home, we had no way to help guests discover the near informative images, ensure the information conveyed in the photos was authentic or advise hosts nearly how to improve the appeal of their images in a scalable way.

Thanks to the recent advancement in computer vision and deep learning, we are able to leverage technology to solve these problems at scale. We started with a project that aimed to categorize our listing photos into different room types. For one thing, categorization makes possible a simple home tour where photos with the same room type tin be grouped together. For another, categorization makes information technology much easier to validate the number of certain rooms and check whether the basic room information is correct. Going forward, we believe there are lots of exciting opportunities to further enhance our knowledge of paradigm content on Airbnb. We will show some examples at the end of this post.
Image Classification
The ability to correctly classify the room type for a given listing photograph is incredibly useful for optimizing the user feel. On the guest side, information technology facilitates re-ranking and re-layout of photos based on distinct room types so that the ones people are most interested in will be surfaced first. On the host side, information technology helps the states automatically review listings to ensure they bide by our marketplace's loftier standards. Accurate photo categorization is the backbone for these cadre functions.
The first batch of room types we sought to classify included Bedrooms, Bathrooms, Living Rooms, Kitchens, Pond Pools and Views. Nosotros look to add other room types based on the needs from product teams.
The room-type classification trouble largely resembles the ImageNet classification trouble except that our model outcomes are customized room- types. This makes the off-the-shelf state-of-the-art deep neural network (DNN) models such equally similar VGG, ResNet and Inception not directly applicable in our case. In that location are a number of great posts online which tell people how to cope with this outcome. Basically we should 1) modify the concluding (top) few layers of the DNN to brand certain the output dimension matches ours and 2) re-train the DNN to certain degree and achieve satisfactory performance. Later a few experiments with these models, we chose ResNet50 as our powerhouse due to its good balance between model performance and ciphering time. To make it compatible with our use case, we added two extra fully continued layers and a Softmax activation in the cease. We also experimented with a few training options, which volition be discussed in the side by side section.
Re-train a Modified ResNet50
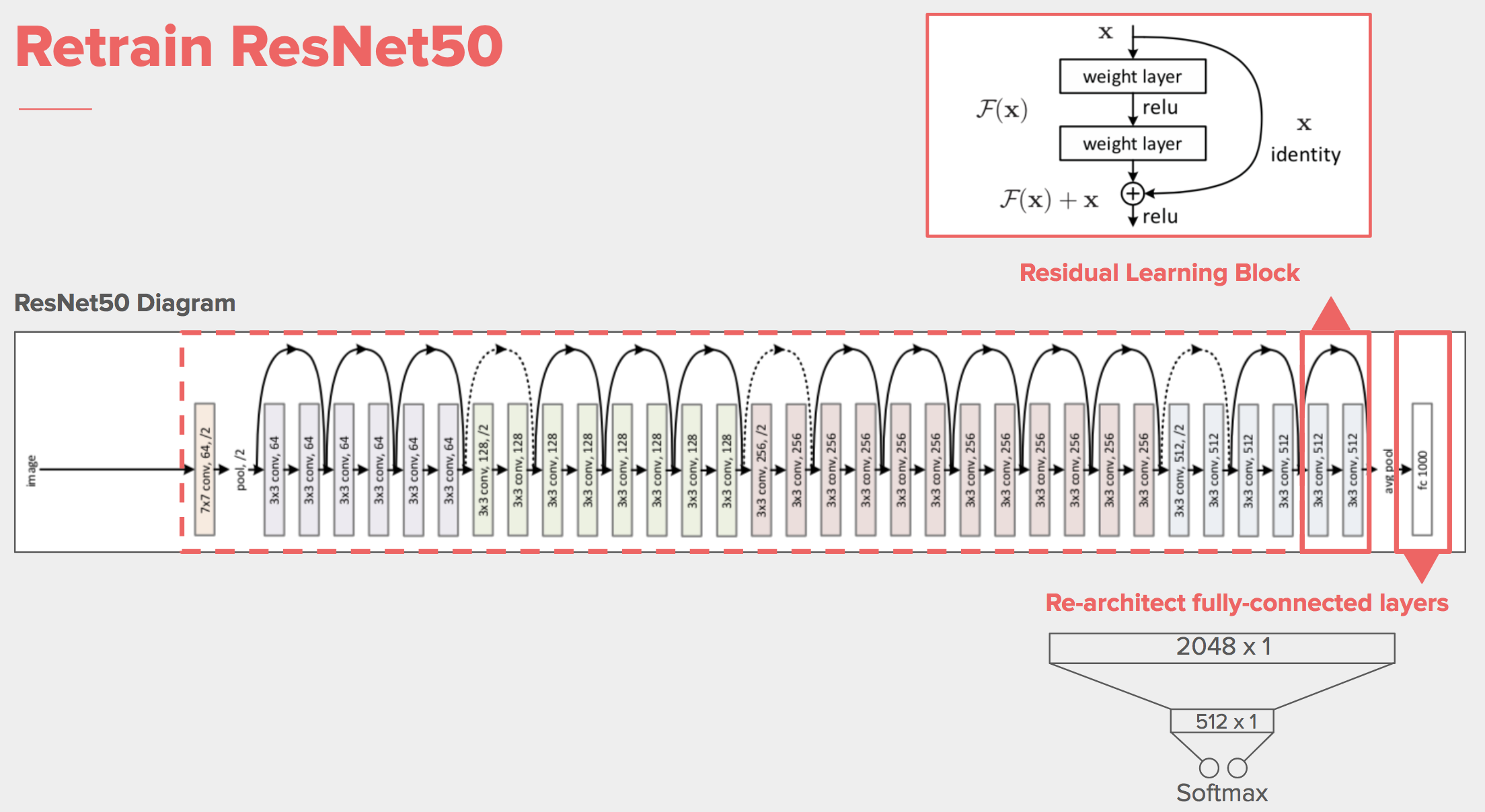
Re-preparation ResNet50 falls in 3 scenarios:
- Go on the base ResNet50 model stock-still and only re-train the added two layers using minimal information. This is too often called fine-tuning.
- Do the aforementioned fine tuning as in 1, but with much more data.
- Re-railroad train the whole modified ResNet50 from scratch.
Most of the online tutorials use the first arroyo because information technology's fast and unremarkably leads to decent results. We tried the first arroyo and indeed got some reasonable initial results. Withal in order to launch high-quality paradigm product, nosotros needed to improve the model performance dramatically — ideally achieving 95%+ precision, and 80%+ recall.
To accomplish high precision and loftier recall simultaneously, nosotros realized using massive data to re-railroad train the DNN was inevitable. However there were 2 major challenges: 1) Fifty-fifty though we had lots of listing photos uploaded by hosts, we didn't accept accurate room-blazon labels associated with them, if any at all. two) Re-training a DNN similar ResNet50 was highly not-niggling — In that location were more than 25 one thousand thousand parameters to railroad train and this required substantial GPU support. These two challenges will be addressed in the next two sections.
Supervision With Image Captions
Many companies leverage third-party vendors to obtain high-quality labels for image data. This is obviously not the most economical solution for the states, when millions of photos need to be labeled. To remainder cost and operation, nosotros approached this labeling problem in a hybrid style. On 1 side, we asked vendors to label relatively small-scale number of photos, normally in thousands or tens of thousands. This chunk of labeled information would be used as a gilt set for us to evaluate models. We used random sampling to get this gilt set and ensured the data was unbiased. On the other side, we leveraged image captions created by hosts equally a proxy for room-type information and extracted labels out of information technology. This idea was huge for us considering it made the expensive labeling task substantially gratis. We only needed a judicious way to ensure that room-blazon labels extracted from image explanation were accurate and reliable.
A tempting method to extract room-type label from image caption is as follows: If a sure room blazon keyword is establish in the explanation of an image, the epitome volition be labeled every bit that type. Nonetheless the real world is more complicated than that. If you examined the results of this rule, you'd exist very disappointed. We found numerous cases where the paradigm explanation was far off the actual content of that image. Below are a few bad examples.

To filter out bad examples like this, nosotros added extra rules when extracting room-type labels from image captions. After several rounds of filtering and checking, the label quality was greatly improved. Beneath is an instance for how we filtered Kitchen data to obtain relatively "clean" Kitchen images.
Due to these extra filters, we lost quite a lot of image data. This was okay for us because even with such an aggressive filtering, we still ended upwards with a few million photos, a few hundred g in each room blazon. More over, the label quality of these photos were now much better. Here we assumed the data distribution didn't shift with the filtering, which would exist validated once nosotros tested out the model on an unbiased golden dataset.
Having said that, nosotros might have been able to use some NLP Techniques to dynamically cluster epitome captions instead of using dominion-based heuristics. However nosotros decided to stay with heuristics for now, and pushed NLP work to the future.
Model Building, Evaluating, and Production
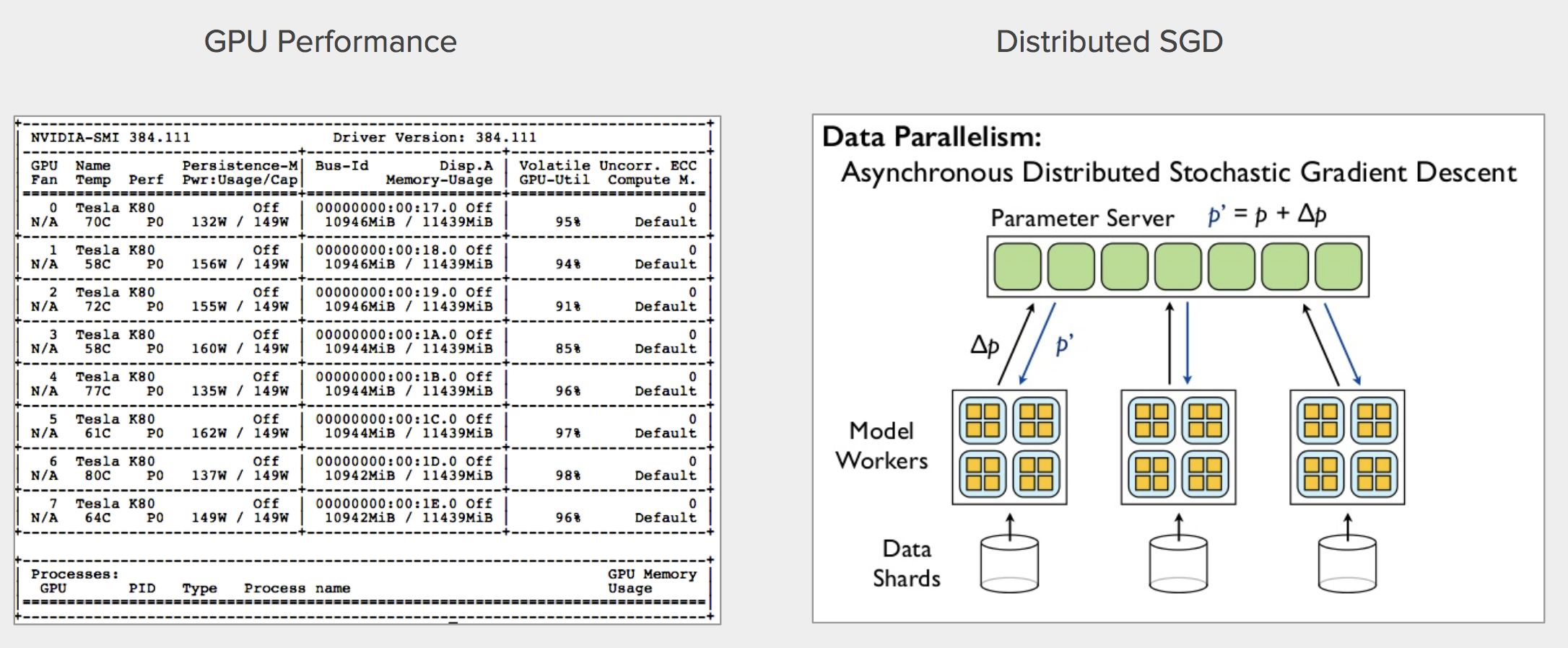
Re-grooming a DNN like ResNet50 using a few one thousand thousand images requires a lot of computational resources. In our implementation, nosotros used an AWS P2.8xlarge Instance with Nvidia eight-core K80 GPU, and sent a batch of 128 images to 8 GPUs per training step. We did parallel grooming with Tensorflow as the backend. Nosotros compiled the model afterward parallelizing it considering otherwise the training wouldn't work. To further speed up grooming, we initialized model weights with pre-trained imagenet weights loaded from keras.applications.resnet50.ResNet50. The best model was obtained after 3 epochs of training, which lasted well-nigh 6 hours. After the model started to overfit and the performance on validation fix stopped improving.
One important annotation is that we built in production multiple binary-class models for dissimilar room types instead of building a multi-class model to cover all room types. This was non platonic but since our model serving was mostly offline, the actress delay due to multiple model calls affected us minimally. We will transit to a multi-grade model in production soon.
Nosotros evaluated our models based on precision and think. We also monitored metrics similar F1 score and accuracy. Their definitions are reiterated as beneath. In a nutshell, precision describes how confident we are near the accuracy of our positive predictions, and recall describes how much percent our positive predictions embrace all bodily positives. Precision and think usually go confronting each other. In our context, nosotros set a high bar (95%) for precision considering when we claim the photograph is a certain room blazon, we should really have a high conviction near that claim.
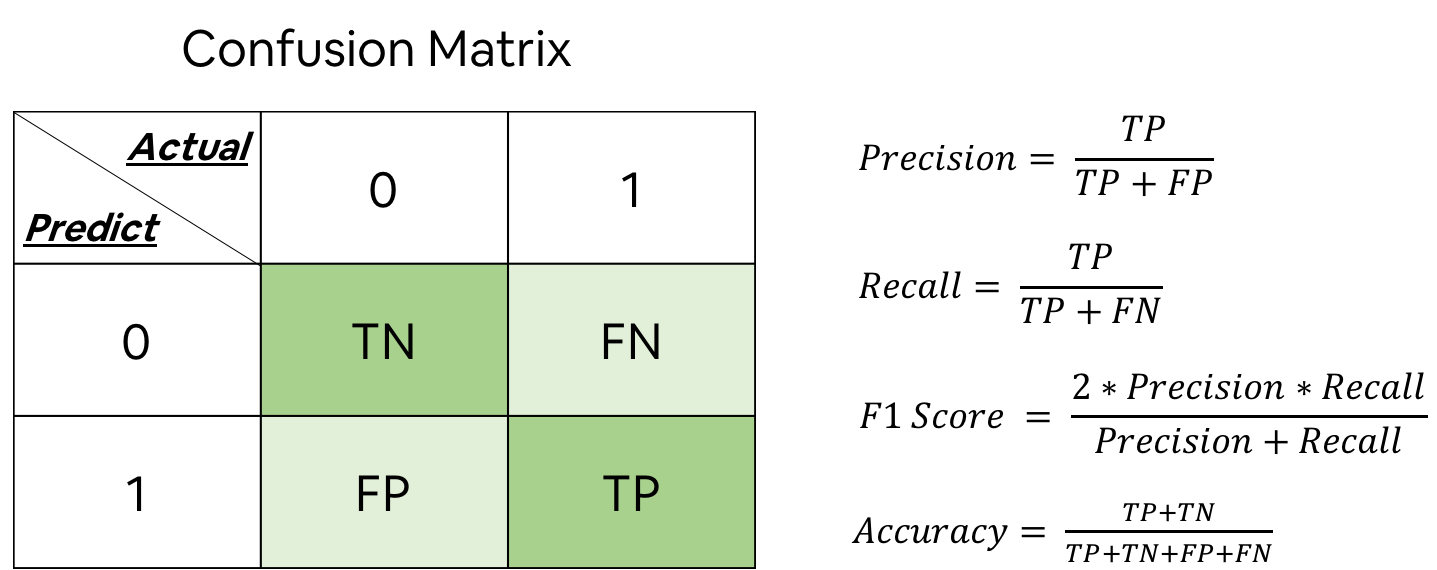
A confusion matrix is the fundamental to summate these metrics. Our model's raw output is a probability score from 0 to 1 for each image. To compute a defoliation matrix for a set up of predictions, one has to outset prepare a particular threshold to interpret the predicted scores into 0 and ane. A precision-retrieve (P-R) bend is and then generated by sweeping the thresholds from 0 to 1. In principle the closer to i the AUC (Surface area Under Curve) of a P-R bend is, the more authentic the model is.
In evaluating the models, we used the same aureate set where the ground truth labels were provided by humans. Interestingly we institute accuracy differed from room blazon to room type. Chamber and Bathroom models were the most accurate ones while other models were less accurate. For brevity, we only testify the P-R curve of a Bedchamber and Living Room here. The cross point of the dotted lines represents the final performance given a particular threshold. We append a summary of the metrics on the chart.
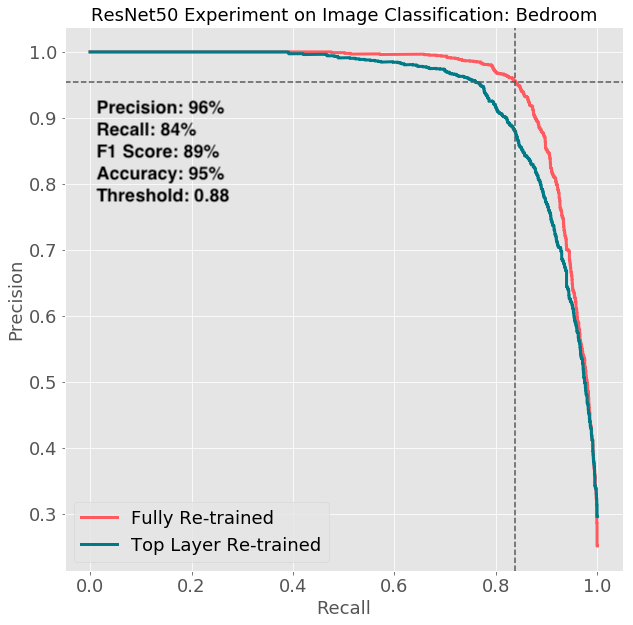
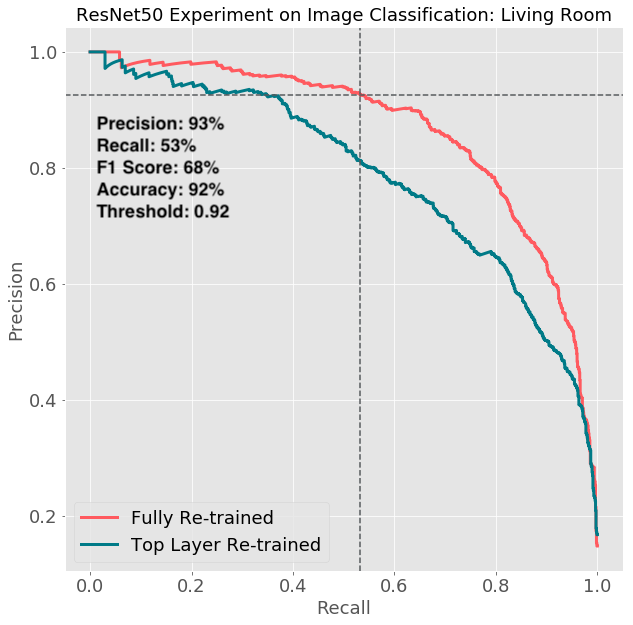
There are two important observations:
- The overall performance of the Bedroom model is much ameliorate than that of the a Living Room. There could exist two explanations: ane) A Bedroom is easier to classify than a Living Room because Bedroom setting is relatively standard while Living Room can take a lot more varieties. ii) The labels extracted from Bedroom photos have higher quality than those extracted from Living Room photos since Living Room photos occasionally too include Dining Rooms or fifty-fifty Kitchens.
- Inside each room type, a fully re-trained model (blood-red bend) has better functioning than the partially re-trained (blue bend) model, and the gap is larger betwixt Living Room models than between Sleeping room models. This suggests re-preparation a full ResNet50 model has different impact for difficult room types.
For the six models we shipped, precision is generally above 95% and recall is by and large above 50%. By setting dissimilar threshold values people can make trade-offs. The model is gear up to power a number of different products across multiple production teams within Airbnb.
The users compared our results of to well-known third-party image recognition APIs. Information technology was reported that the in-firm model overall outperformed 3rd-party generic models. This implies by taking advantage of your own information, you have a chance to outperform even the industry state-of-the-art model for a detail task you are interested in.
At the terminate of this section, we'd like to showcase a few concrete examples that exemplify the power of this model.



Beyond Nomenclature
When doing this projection, we as well tried a few interesting ideas across room type nomenclature. We want to testify two examples here and requite people an idea how exciting these issues are.
Unsupervised Scene Classification
When we first tried out room blazon classification using pre-trained ResNet50 model, nosotros generated prototype embeddings (2048x1 vectors) for listing cover- folio photos. To translate what these embeddings meant, we projected these long vectors onto a 2d plane using PCA techniques. Much to our surprise, the projected data are naturally amassed into two groups. Looking into these two clusters, nosotros found that the left grouping were near exclusively indoor scenes and the right group were almost exclusively outdoor scenes. This meant without any re-training and simply by setting a cut line on the first main component of the image embedding, we were able determine indoor and outdoor scenes. This finding opened the door to some really interesting domain where transfer learning (embedding) met unsupervised learning.

Object Detection
Some other surface area that nosotros tried pursuing was object detection. A pre-trained Faster R-CNN model on Open up Images Dataset already provided stunning results. As yous see in the instance below, the model is able to detect Window, Door, Dining Table and their locations. Using Tensorflow Object Detection API, we did some quick evaluations on our listing photos. A lot of the home civilities could be detected using the off-the-shelf result. In the futurity, we plan to retrain the Faster R-CNN model using Airbnb'southward customized amenity labels. Since some of these labels are missing in the open source data, We volition likely create labels on our own. With these algorithm-detected civilities, we are able to verify the quality of the listings from hosts and make it much easier for guests to detect homes with specific assiduities needs. This will push button the frontier of photograph intelligence at Airbnb to the next level.

Determination
Here are a few key take-aways that might be helpful for other deep learning practitioners:
Outset, deep learning is cypher simply one particular kind of supervised learning. One cannot overestimate the importance of high-quality labels to the data. Since deep learning usually requires a significant amount of preparation data to accomplish land-of-the-fine art performance, finding an efficient manner to do labeling is crucial. Fortunately nosotros plant a hybrid approach which is economical, scalable and reliable.
Second, grooming a DNN like ResNet50 from scratch tin can be quite involved. Attempt to start in a unproblematic and fast way — train only tiptop layers using a small-scale dataset. If yous practise take a large trainable dataset, re-grooming a DNN from scratch might give you state-of-the-fine art performance.
3rd, parallelize the preparation if you tin. In our case we gained about 6x (quasi-linear) speed-upward past using 8 GPUs. This makes building a complex DNN model computationally viable and it is much easier to iterate over hyper parameters and model structures.
Interested in applying deep learning on high-impact issues like this? We're always looking for talented people to bring together our Data Science and Analytics team !
This work is in collaboration with Krishna Puttaswamy , Xiaohan Zeng and Alfredo Luque . People across the visitor helped launch this feature in products. We would also like to thank the contributors of open source libraries such as Keras, Tensorflow, Open Images Data, ImageNet and the original inventors of ResNet. We benefit tremendously from this friendly open source customs. Finally, we thank Jeff Feng and Rebecca Rosenfelt for their kind assistance in proofreading.
namatjiraresses43.blogspot.com
Source: https://medium.com/airbnb-engineering/categorizing-listing-photos-at-airbnb-f9483f3ab7e3
0 Response to "Trouble Uploading Photos to New Airbnb Listing"
Post a Comment